État de l'art
d'Elasticsearch avec PHP

@damienalexandre

![]()
- 🐘 Lead développeur PHP ;
- 🔎 Consultant / Formateur Elasticsearch ;
- #emoji #guinness #velotaf #végé #metal
Révisons les bases
Elasticsearch
- Un outil, pas une solution ;
- Base de données NoSQL / orientée Document ;
- Index inversé distribué ;
- Pas de transaction, pas de relation.
Utilisations
- 🔎 Moteur de recherche full-text ;
- 📚 Base NoSQL ;
- 📃 Stockage et analyse de logs ;
- 📊 Statistiques / BI ;
- 🤯 Machine Learning, monitoring applicatif, outil de présentation, dashboard...
Ça ne sert pas à
- 🔥 Conserver vos stocks, vos sessions...
- 💽 Stocker des données critiques ;
- 📃Effectuer des transactions ;
- 👕
Étendre le linge - 📦
Aller chercher un colis à La Poste
Pardon, c'est ma TODO LIST.
Cluster, Node et Shard

Avec PHP

Besoin d'appels HTTP
- Contrairement à MongoDB ou PostgreSQL, pas d'extension nécessaire :
- HTTP ?
\file_get_contents() - JSON ?
\json_decode() - Tout est natif !
✔️ Pour conclure ✔️
$results = \json_decode(
file_get_contents('http://localhost:9200/_search'),
true
);Merci ! Des questions 🙏🏽 ? Il nous reste 30 minutes.
Avec PHP
Les paquets existants
elasticsearch/elasticsearch-php= Officiel ;ruflin/elastica;madewithlove/elasticsearcher(5.x) ;friendsofsymfony/elastica-bundle;doctrine/searchSurprise !- Beaucoup de code non maintenu, inutile,...
Elastica
- Elasticsearch évolue vite... pas les librairies
- Chaque besoin est différent
- Moi je vote Elastica !
Elastica
$params = [
'query' => [
'bool' => [
'must' => [
'match' => [
'category' =>
'Beurre'
]
]
]
]
];
$bool = new BoolQuery();
$bool->addMust(
new Match(
'category',
'Beurre'
)
);
Utilisez Elastica,
les Array c'est bon pour un Hello World !
Indexer un document
$index = $client->getIndex('app');
$doc = new Document(
// Document ID
42,
// Document data is an array!
['username' => 'hans', 'likes' => ['2', '3', '5']]
);
$index->addDocuments([$doc]);
Encore des Array !
- Un Document Elastica est un array, transformé en JSON ;
- Je n'aime pas les array ;
- Larry Garfield :
If you're still using nested associative arrays for that, You're Doing It Wrong(tm).
Use associative arrays basically never / Never type hint on arrays
Avec des DTO,
on y verrait plus clair !
Data transfer object
Avec des DTO
Manipuler des objets en entrée et en résultat,
comme avec Doctrine.
// Création du DTO
$product = new Product();
$product->setName('Beurre Salé');
$product->setCategory('Produits vitaux');
// Indexation
$doc = new Document(43, $product);
$index->addDocuments([$doc]);
Nous allons devoir coder ! C'est pour ça qu'on est là !
Des briques à coder
- IndexBuilder : créer les Index avec leur Mapping ;
- Indexer : créer les Document, les pousser dans l'Index ;
- ResultBuilder : construire nos résultats de recherche ;
- IndexUpdater : mettre à jour en temps réel ;
- SearchRepository : contruire les Search Elastica ;
- QueryBuilder : morceaux de requêtes Elastica réutilisables.
L'indexation
Créer un index
PUT /app
{
"settings": {
"number_of_shards": 1,
"analysis": {
"analyzer": {
"yolo": {
"tokenizer": "standard"
}
}
}
},
"mappings": {
"properties": {
"name": { "type": "text", "analyzer": "yolo" },
"ref": { "type": "text", "analyzer": "yolo" }
}
}
}↙️ ️Beaucoup de répétitions
YAML > JSON
filter:
app_french_stemmer:
type: stemmer
language: light_french
analyzer:
app_french_heavy:
tokenizer: icu_tokenizer
filter:
- app_french_elision
- icu_folding
- app_french_stemmer
settings:
number_of_shards: 1
# Include analyzers.yaml here
mappings:
properties:
name:
type: text
analyzer: app_standardhttps://noyaml.com/
Mais j'aime toujours YAML.
🎓 Protip © YAML anchor
mappings:
properties:
first_name: &simple_text
type: text
fields:
raw: { type: keyword }
stemmed: { type: text, analyzer: french }
last_name: *simple_text
company: *simple_text
city:
<<: *simple_text
fields:
raw: { type: keyword }
mappings:
properties:
first_name:
type: text
fields:
raw: { type: keyword }
stemmed: { type: text, analyzer: french }
last_name:
type: text
fields:
raw: { type: keyword }
stemmed: { type: text, analyzer: french }
company:
type: text
fields:
raw: { type: keyword }
stemmed: { type: text, analyzer: french }
city:
type: text
fields:
raw: { type: keyword }IndexBuilder.php
public function createIndex($indexName): Index
{
// Read the YAML's
$mapping = Yaml::parse(file_get_contents($indexName .'_mapping.yaml'));
$analyzer = Yaml::parse(file_get_contents('/analyzers.yaml'));
// Merge the YAML's
$mapping['settings']['analysis'] = array_merge_recursive(
$mapping['settings']['analysis'] ?? [],
$analyzer
);
// Build Index name
$realName = sprintf('%s_%s', $indexName, date('Y-m-d-His'));
$index = $this->client->getIndex($realName);
// Actually create the Index with Mapping
$index->create($mapping);
return $index;
}🎓 Protip © Index Version
Versionnez vos index !
Elasticsearch propose des alias d'index.
$realName = sprintf('%s_%s', $indexName, date('Y-m-d-His'));
$index = $this->client->getIndex($realName);
$index->create($mapping);
public function markAsLive(Index $index, $indexName): Response
{
$data = ['actions' => []];
$data['actions'][] = ['remove' => ['index' => '*', 'alias' => $indexName]];
$data['actions'][] = ['add' => ['index' => $index->getName(), 'alias' => $indexName]];
return $this->client->request('_aliases', Request::POST, $data);
}
🎓 Protip © Dynamic
Par défaut le mapping est dynamique,
il se crée tout seul ! 🎉
PUT /app/_doc/1
{ "rating": 9 }
PUT /app/_doc/2
{ "rating": 9.9 }
GET /app/_mapping
> { "rating": { "type": "long" }}
Oops, mon 9.9 perd sa décimale !
🎓 Protip © Dynamic
Désactivez le mapping dynamique. C'est bon
pour les tutos, pas pour les pros.
mappings:
dynamic: false
properties:
rating:
...
👿🔥🔥 dynamic: true, c'est LE MAL ! 🔥🔥👿
Indexer.php
Indexer un Document avec Elastica
// Via Array
$doc = new Document(43, ['name' => 'Beurre salé']);
$index->addDocuments([$doc]);
// Or via JSON
$doc = new Document(43, '{"name": "Beurre salé"}');
$index->addDocuments([$doc]);
Serialiser nos DTO
Un JSON pour Elastica
Pour passer d'un DTO PHP à un JSON :
\json_encode(par défaut si on donne un Array)ObjectNormalizerdesymfony/serializerJMSSerializerJane...
Nous devons pouvoir dénormaliser aussi,
en résultat de recherche !
Serializer de Symfony
use Symfony\Component\Serializer as Serializer;
$serializer = new Serializer\Serializer([
new Serializer\Normalizer\ArrayDenormalizer(),
new Serializer\Normalizer\ObjectNormalizer(),
], [
new Serializer\Encoder\JsonEncoder()
]);
$serializer->serialize($product, 'json');
{"name":"WashWash 3000","category":"Dentifrice"}
Serializer de Symfony
// Super DTO
$product = new Product();
$product->setName('Beurre DOUX 😆 🤭');
// Document Elastica
$doc = new Document(
43,
$serializer->serialize($product, 'json')
);
// Indexation
$index->addDocuments([$doc]);
Le DTO est indexé 👌🏽
Jane : Tools for generating PHP Code
ObjectNormalizer est plutôt lent car il va lire
votre DTO via \Reflection.
Jane va générer le DTO et ses Normalizer
en pure PHP via un JSON Schema.
Installer Jane
composer require --dev jane-php/json-schema "^4.0"
composer require jane-php/json-schema-runtime "^4.0"
composer require --dev friendsofphp/php-cs-fixer "^2.7.3"
# Run the code generator
php vendor/bin/jane generate \
--config-file=jane-elasticsearch-dto-config.php
Installer Jane
return [
'json-schema-file' => '/es.json',
'root-class' => 'Model',
'namespace' => 'Elasticsearch',
'directory' => '/generated',
];
{
"$schema": "http://json-schema.org/draft-07/schema#",
"definitions": {
"Product": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"category": {
"type": "string"
}
}
}
}
}Et 💥 BOOM 💥
$ tree generated/
generated
├── Model
│ └── Product.php
└── Normalizer
├── NormalizerFactory.php
└── ProductNormalizer.php
Product.php
namespace Elasticsearch\Model;
class Product
{
protected $name;
protected $category;
// + getter and setters
}
ProductNormalizer.php
namespace Elasticsearch\Normalizer;
class ProductNormalizer implements DenormalizerInterface, NormalizerInterface, DenormalizerAwareInterface, NormalizerAwareInterface
{
use DenormalizerAwareTrait;
use NormalizerAwareTrait;
public function supportsDenormalization($data, $type, $format = null)
{
return $type === 'Elasticsearch\\Model\\Product';
}
public function supportsNormalization($data, $format = null)
{
return $data instanceof \Elasticsearch\Model\Product;
}
public function denormalize($data, $class, $format = null, array $context = [])
{
$object = new \Elasticsearch\Model\Product();
if (property_exists($data, 'name')) {
$object->setName($data->{'name'});
}
if (property_exists($data, 'category')) {
$object->setCategory($data->{'category'});
}
return $object;
}
public function normalize($object, $format = null, array $context = [])
{
$data = new \stdClass();
if (null !== $object->getName()) {
$data->{'name'} = $object->getName();
}
if (null !== $object->getCategory()) {
$data->{'category'} = $object->getCategory();
}
return $data;
}
}NormalizerFactory.php
namespace Elasticsearch\Normalizer;
class NormalizerFactory
{
public static function create()
{
$normalizers = [];
$normalizers[] = new \Symfony\Component\Serializer\Normalizer\ArrayDenormalizer();
$normalizers[] = new \Jane\JsonSchemaRuntime\Normalizer\ReferenceNormalizer();
$normalizers[] = new ProductNormalizer();
return $normalizers;
}
}Jane + Serializer
$normalizers = \Elasticsearch\Normalizer\NormalizerFactory::create();
$encoders = [
new JsonEncoder(
new JsonEncode([JsonEncode::OPTIONS => \JSON_UNESCAPED_SLASHES]),
new JsonDecode([JsonDecode::ASSOCIATIVE => false])
)
];
$serializer = new Serializer($normalizers, $encoders);
// Super fast Product serializer!
Jane
Vous pouvez l'utiliser pour tous vos besoins
DTO / Normalisation.
Une indexation complète
- Requête à la base de données ;
- Loop sur tous les résultats ;
- Construction des DTO, JSON et Document ;
- Ajout dans un Array
$docs[];
- Appel à
$index->addDocuments($docs);qui produit l'appel HTTP à l'API Bulk.
Ça va pas du tout scaler 💥
Une indexation complète
- Requête à la base de données ;
- Loop sur tous les résultats ;
- Construction des DTO, JSON et Document ;
- Ajout dans un Array
$docs[]; - Quand le Array atteint un seuil,
appel à$index->addDocuments($docs);
- Appel à
$index->addDocuments($docs);final.
Une indexation complète
Vous aurez besoin d'une queue d'indexation locale :
$client = new Client();
$indexer = new \JoliCode\Elastically\Indexer($client);
$index = $client->getIndex('app');
$indexer->scheduleIndex($index, $doc1);
$indexer->scheduleIndex($index, $doc2);
$indexer->scheduleIndex($index, $doc3); // GO BULK
$indexer->scheduleIndex($index, $doc4);
$indexer->scheduleIndex($index, $doc5);
$indexer->flush(); // Et ici on force
Elastically c'est une petite lib pour simplier nos implémentations...
🎓 Protip © Bulk
Un Bulk répond toujours le code HTTP 200 !
Il faut toujours en lire la réponse :
{
"took" : 22,
"errors" : true,
"items" : [
{
"index" : {
"_index" : "app",
"_type" : "_doc",
"_id" : "1",
"status" : 400,
"error" : { … }
}
}
]
}Nos résultats de recherche
Récupérer notre DTO
Elastica répond avec des Elastica\Result,
dont "data" est un Array associatif.
$results = $index->search(
new \Elastica\Query\Match('name', 'washwash')
);
// Elastica\ResultSet:
// results: Elastica\Result[]
Result.php
namespace JoliCode\Elastically;
use Elastica\Document;
use Elastica\Result as ElasticaResult;
class Result extends ElasticaResult
{
protected $model;
// Getter + Setter
}Extension du Result d'origine.
Elastica\ResultSet\BuilderInterface
Nous pouvons avoir notre propre builder de résultats.
$result = new Result($hit);
$result->setModel(
$this->serializer->denormalize(
$result->getSource(),
\Product::class
);
);Et voilà nous avons des Product dans nos résultats !
Pour l'utiliser
À chaque recherche :
use \JoliCode\Elastically\ResultSetBuilder;
$search = $index->createSearch(
$query,
null,
new ResultSetBuilder($serializer)
);
Notre Search va répondre des Product !
La création de Document
Oui elles sont au beurre salé.La dénormalisation
en NoSQL
- De quels champs avez-vous besoin à l'affichage ?
- De quels champs avez-vous besoin à la recherche ?
Envoyez le nécessaire,
indexez le minimum !
La dénormalisation
en NoSQL
- Un Article est lié à un Auteur ;
- Nous voulons chercher par Auteur ;
- Mettre à jour un Auteur ? Potentiellement des milliers de mises à jour ! 💥

Adieu les relations !
- Sans jointures, mises à jour plus complexes ;
- Certaines requêtes difficiles ;
- Compromis entre tout dénormaliser et devoir faire plusieurs requêtes.
Ne dénormalisez pas
toute votre BDD !
Mapping ≠ Document
- Le Mapping : vos champs dans l'index Lucene ;
- Le Document : vos données à vous ;
- Ne pas corréler les deux.
{
title: "Vive la Guinness",
url: "https://joli.beer/"
}
title: [vive] [guinness]
"url" n'est pas indexé !
🎓 Protip © Clé JSON
Ne mettez pas de valeurs en clé de JSON.
"Mapping explosion" en devenir ! 💥
🎓 Protip © Clé JSON
Elasticsearch limite à 1000 le nombre de champs.
Et vous gagnez la possibilité de chercher par Id.
Connexion à la base de données
Propager les mises à jour
-
Notifier un bus de messages (traitement asynchrone) :
- Event Doctrine ;
- Event applicatif ;
- Trigger de base de données.
- Logstash (inputs-jdbc) ;
-
Indexer lors duflush()💥.
Pourquoi pas synchrone ?
- Latence par défaut de 1 seconde (refresh) ;
- Connexion HTTP à ouvrir ;
- Ralentissement de l'application ;
- Elasticsearch down = perte de la mise à jour ;
- Autant indexer en asynchrone donc !
Un worker d'indexation
- Déléguez-lui le plus de travail possible ;
- Payload très léger :
- Arbre des relations dénormalisées à calculer ici !
Quelques conseils
Accélérer l'indexation
- Souvent PHP le problème...
- Faire des bulk, jouer avec leur taille ;
- Blackfire.io pour trouver où vous perdez du temps ;
- Utilisez un Serializer rapide (coucou Jane 👋🏽) ;
- Doctrine
iterate().
-
Côté Elasticsearch :
- Augmentation du
refresh_interval; - Désactivation des replicas.
- Augmentation du
Pertinence des résultats
- La pertinence c'est subjectif ;
?explain=truedans les URL ;- Vous devez mettre en place des tests ;
- Un bon analyzer & sa recherche !
Le SQL me manque
POST /_sql?format=txt
{
"query": "SELECT * FROM app LIMIT 5"
}
category | name
---------------+---------------
Dentifrice |WashWash 3000
Dentifrice |WashWash 3200 S
C'est dans X-Pack Basic donc gratuit.
POST /_sql/translate pour obtenir le Query DSL.
Client Node

Placez un Node Elasticsearch sur vos frontaux PHP.
Utilisez ICU
- Plugin officiel
analysis-icu; - Meilleur support du Français :
- Ligature :
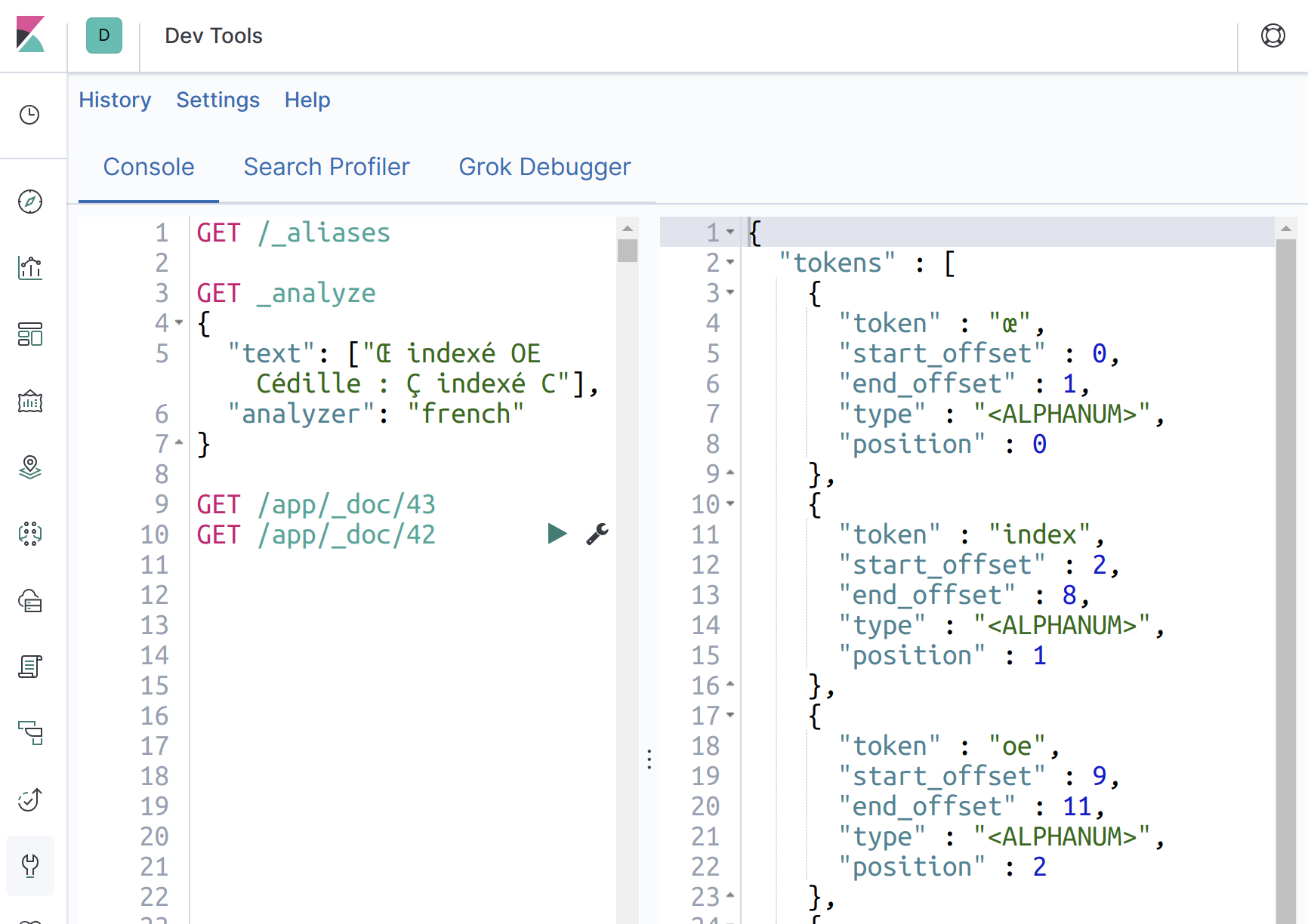
ŒindexéOE; - Cédille :
ÇindexéC;
- Ligature :
- Mais aussi les autres langues (CJK)...
- Collation pour trier !
🌼 Utilisez ICU 🌼
MAIS SURTOUT ça ajoute le support des Emoji !
- Tokenisation des emoji ;
- Ils portent un sens, c'est du contenu !
- https://github.com/jolicode/emoji-search.
🥔 => 🥔, potato, vegetable, food
N'utilisez pas QueryString
- Votre client veut :
Poney AND Horse OR Anima*? - Vous avez utilisé la clause
query_string? - Vous allez avoir des problèmes ! 💥
- Utilisez un parseur et faites vous même la requête ! Avec
netgen/query-translator; - Ou
simple_query_string👌🏽.
Kibana = PHPStorm
N'exposez pas Elastic
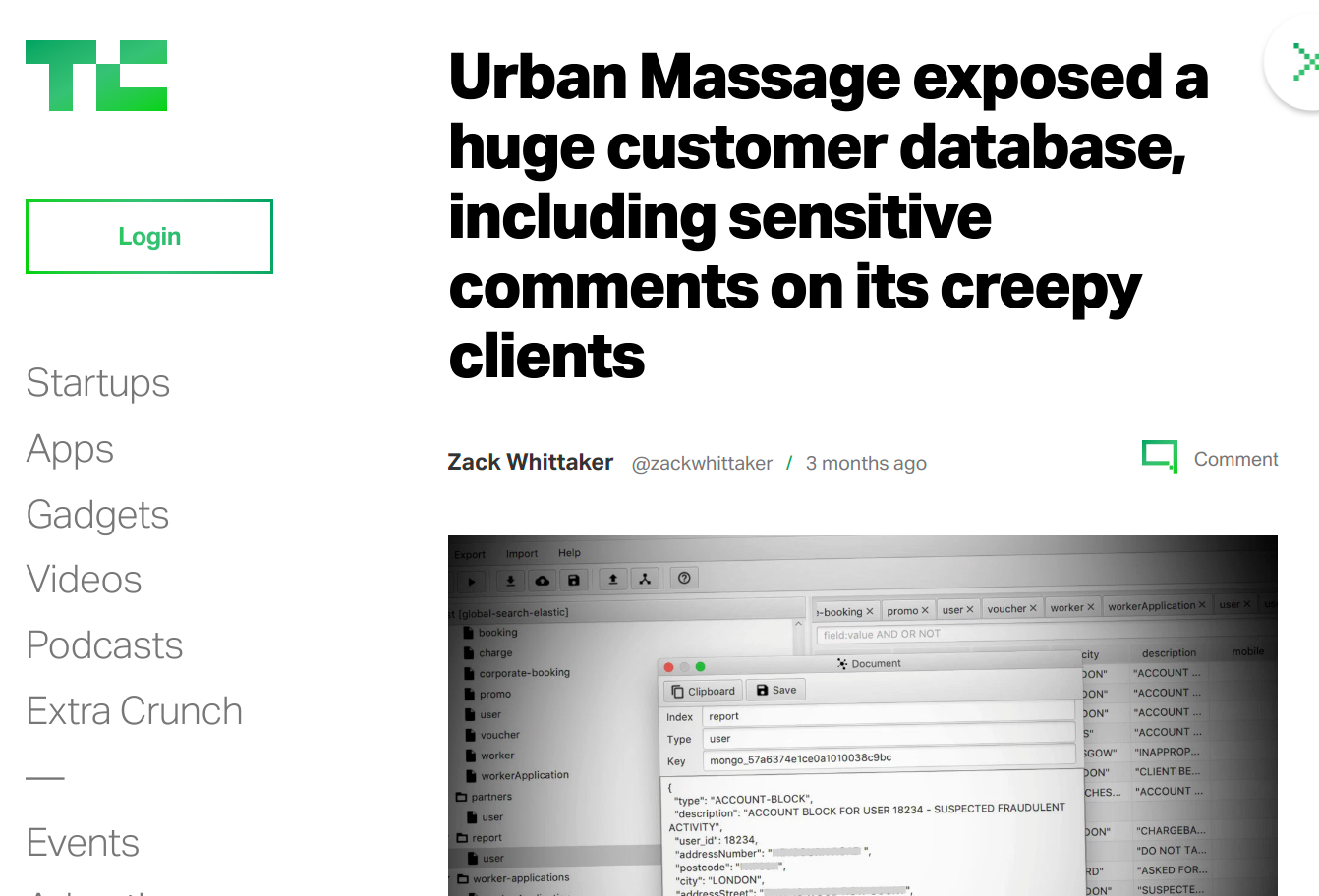
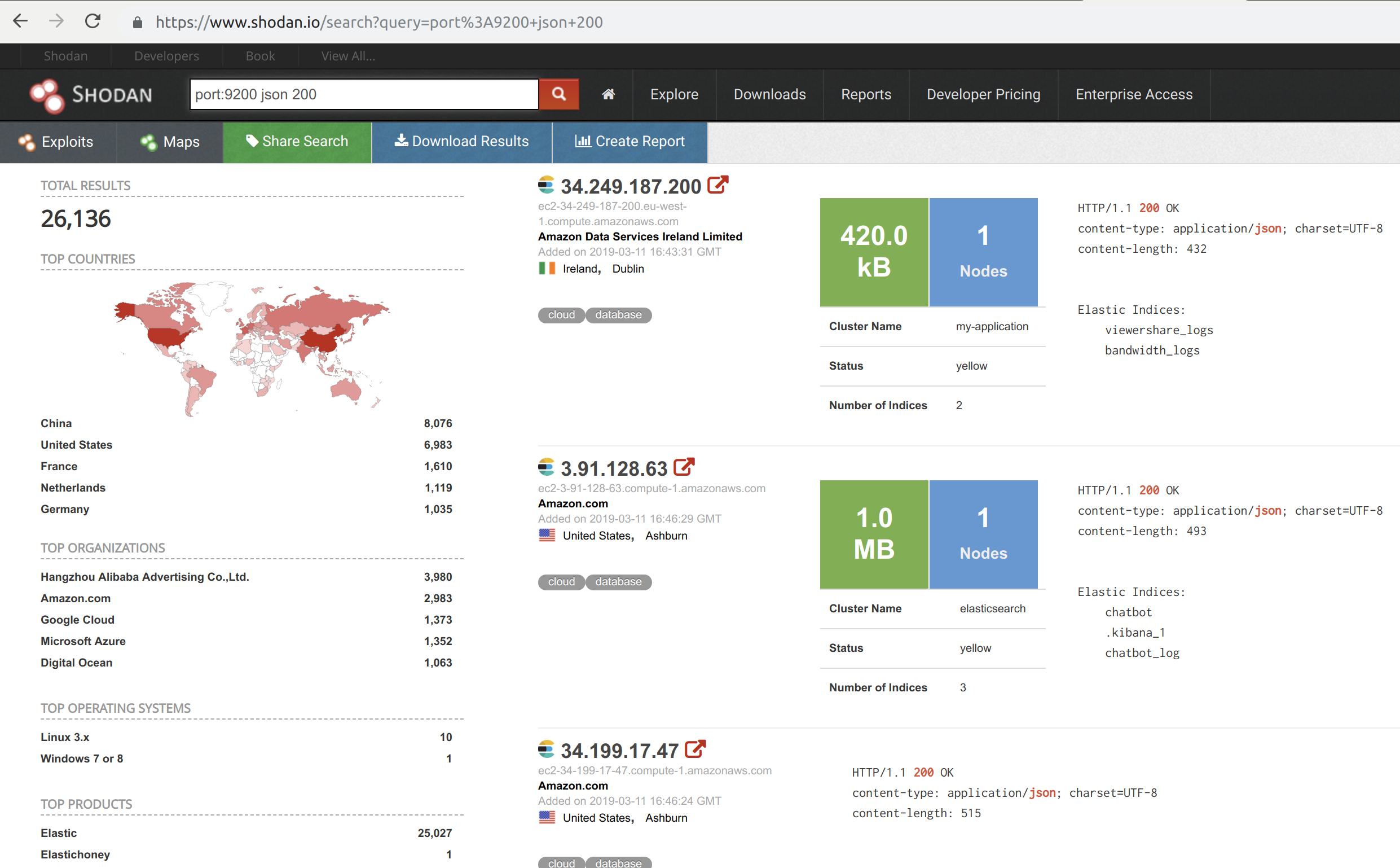
Monitorez votre Elasticsearch

N'hébergez pas Elasticsearch ?
- https://www.elastic.co/cloud/
- https://aws.amazon.com/fr/elasticsearch-service/ (qui vient de lancer Open Distro For Elasticsearch !)
- https://qbox.io/
- ...
Merci pour votre écoute !
❓ Questions ❓
TL;DR: Évitez les implémentations clés en main, utilisez Elastica, manipulez des DTO, déclarez vos mappings en YAML, testez Jane, mangez 5 fruits et légumes.
https://github.com/jolicode/elastically
@damienalexandre
coucou@jolicode.com
Crédit photos
Priscilla Du Preez
Aaron Burden
Suzanne D. Williams
Anthony Martino
Alexandre Godreau
David Clode
Vincent Botta
Brooke Lark
Remerciements
Merci à la team JoliCode et à Perrine.
Nicolas Ruflin pour avoir créé Elastica
et Joël Wurtz pour Jane.