Pourquoi
strlen("🍕") != 1 ?
Et la petite histoire d'Unicode
@damienalexandre

PHP, Elasticsearch, Symfony, Emoji
![]()
Rappel des bases
- Un ordinateur parle en 1 et en 0
- Nous voulons parler en texte
- Il faut traduire les lettres en bits
- Et inversement
Il a fallu se mettre d'accord
⌨ 📠 💻 🖨
L'encodage
Une liste de règles pour transformer une donnée dans les deux sens.
Dire que « 01100001 » vaut « a ».
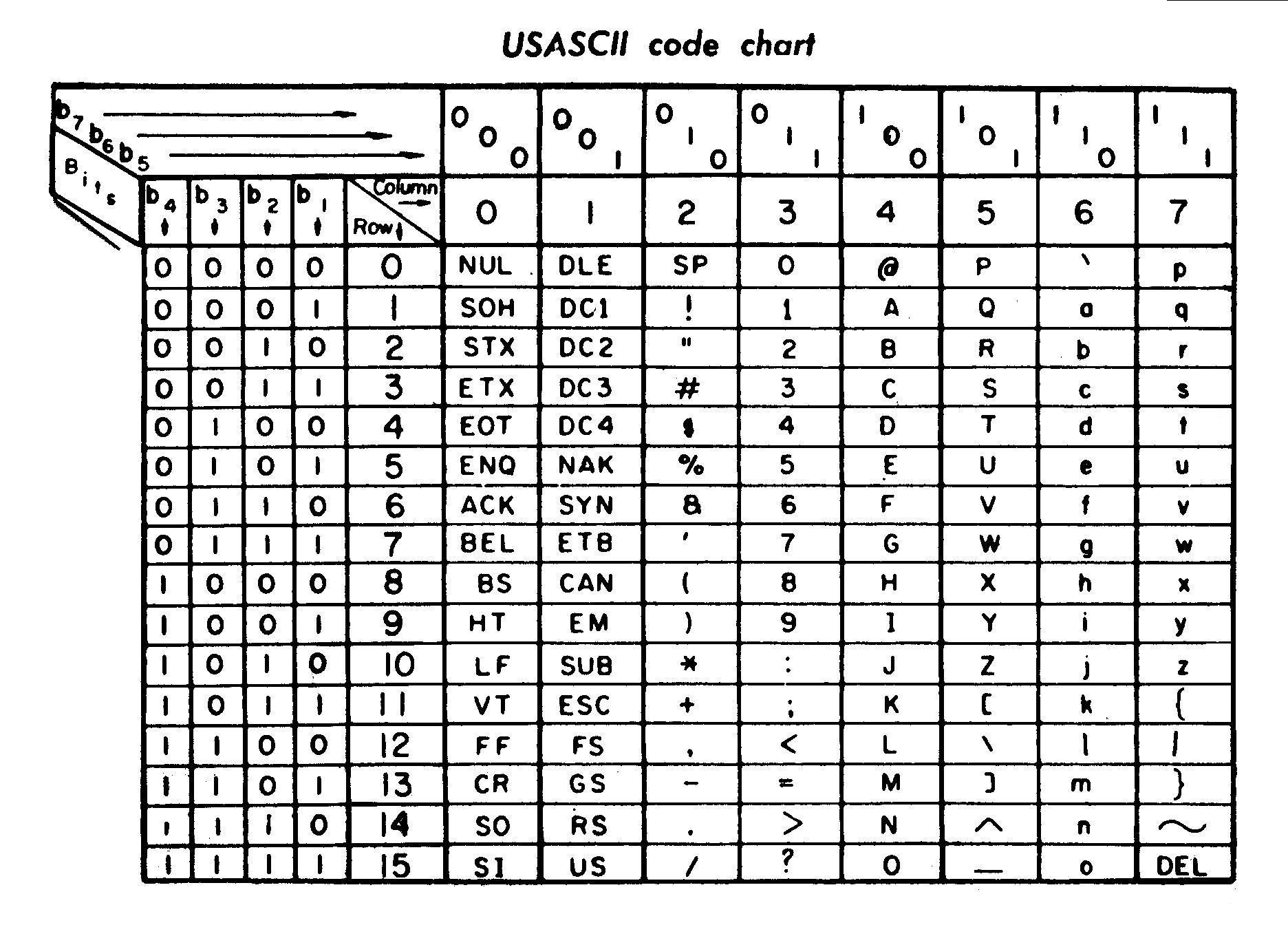
ASCII
🇺🇸 American Standard Code for Information Interchange
Publié en 1963,
7 bits par caractère, donc 127 possibilités.
Avant ASCII c'est un peu le chaos...
Pas top pour le reste du monde
- Allemand : Schildkröte 🐢
- Suédois : Skål! 🍻
- Français : Éléphant 🐘
Avec seulement 95 lettres imprimables, on ne va pas bien loin…
Il reste 1 bit !
- En 1972, les premiers CPU 8 bits arrivent
- Passer à 8 bits permet de mettre 255 caractères
- Les européens se disent : « voilà notre chance ! »
- Chaque pays crée sa variante d'ASCII
é, ß, ü, ä, ö, å
Arrivée de ISO-8859 & co
- ISO 8859-2 Western and Central Europe
- ISO 8859-3 Turkish, Maltese plus Esperanto
- ISO 8859-4 Lithuania, Estonia, Latvia and Lapp
- ISO 8859-5 Cyrillic alphabet
- ISO 8859-6 Arabic
- ISO 8859-7 Greek
- ISO 8859-8 Hebrew
- ISO 8859-9 Western Europe with amended Turkish
Arrivée de ISO-8859 & co
- ISO 8859-15 Added the Euro sign from ISO 8859-1
- ISO 8859-11 Thai
- ISO 8859-14 Celtic languages
- Windows-1253 for Greek
- Windows-1254 for Turkish
- Windows-1255 for Hebrew
- Windows-1258 for Vietnamese
- …
Et Internet arriva
- On s'échange des contenus dans plusieurs langues
- "Skål!" означает здоровье на шведском языке.
- 🇸🇪 🇷🇺
- Deviner l'encodage d'un document... ça marche pas trop
- Hacker ASCII a ses limites
L'age d'or du Mojibake
L'ISO-8859-1 c'est génial !
Vous voulez voir du Mojibake ?
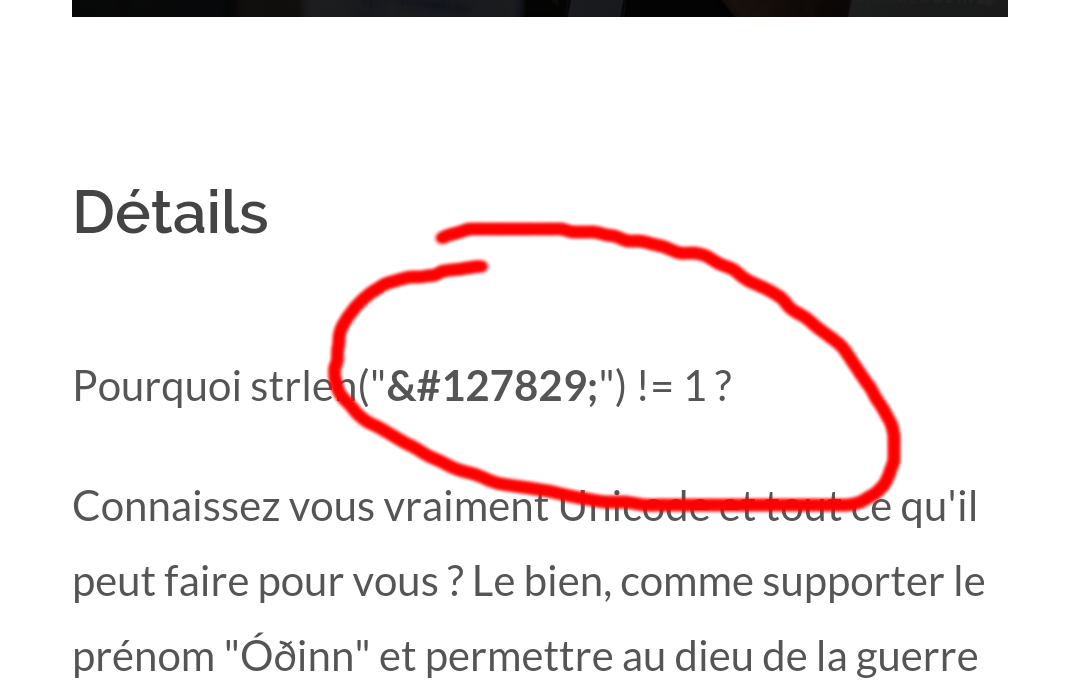
Soumettre une conférence avec un Emoji dans le titre...
Désolé les organisateurs ;-)


Introducing UNICODE
Publié en 1991,
avant la Playstation, le HTML et les Pokémons.

Unicode 1.0
- 65536 code points disponibles, pas mal !
- Stocké sur 16 bits
- 1 caractère = 2 octets (UCS)
- Adopté par JavaScript, C, Java...
- Beaucoup trop petit !
UTF et Unicode 2.0
- Publié en Juillet 1996
- Unicode ne parle plus en caractères mais en code point
- 1,114,112 code points possibles
- Unicode = la liste des caractères
- UTF = l'encodage
Les différents UTF
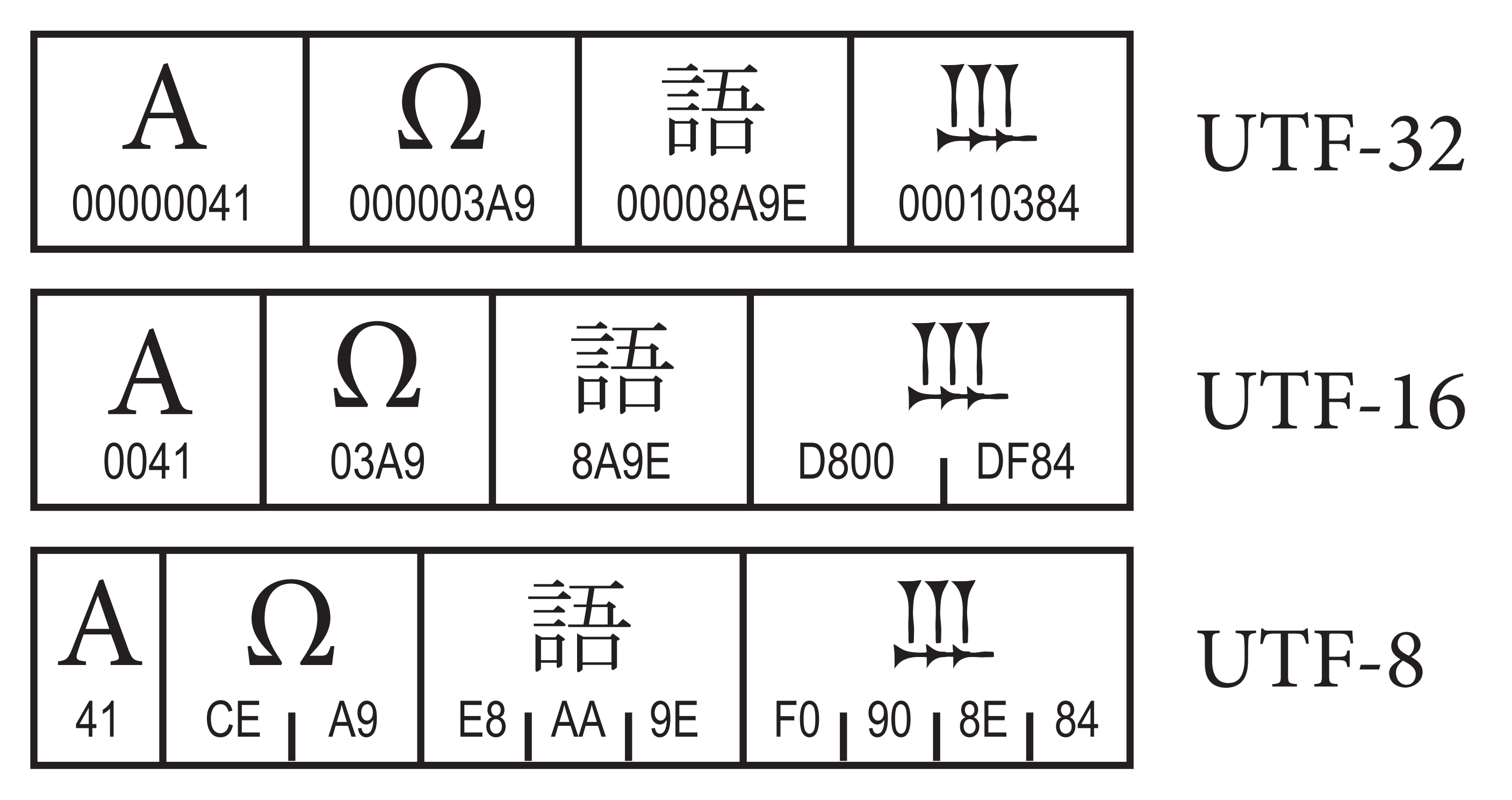
Comment on compte la longueur d'un texte ?
- On sait que du texte c'est une suite d'octets
- En fonction de l'encodage, ces octets ont un sens
- Certains caractères peuvent être composés (é !== e + ◌́)
- On compte en code point ? En octet ? En graphème ?
- La lettre "Œ" par exemple, c'est 1 ou 2 ?
Œ, l'e dans l'o
- Unicode Character 'LATIN CAPITAL LIGATURE OE' (U+0152)
- En UTF-8 il faut deux octets : 0xC5 et 0x92
- Pour information, il est présent dans ISO-8859-15 mais pas dans ISO-8859-1 !
La taille de Œ
// PHP :
echo strlen("Œ"); // 2, nombre d'octets bête et méchant
echo mb_strlen("Œ"); // 1
// JavaScript :
'Œ'.length; // 1
// Python :
>>> len('Œ') // 2
>>> len(u'Œ') // 1La taille de 🍕
// PHP :
echo strlen("🍕"); // 4, nombre d'octets bête et méchant
echo mb_strlen("🍕"); // 1
// JavaScript :
'🍕'.length; // 2
// Python :
>>> len('🍕') // 4
>>> len(u'🍕') // 1Taille en octets, sauf JavaScript
- En JavaScript si vous sortez de la BMP, UTF-16 nécessite deux paires d'octets
- Héritage de Unicode 1.0 (UCS)
- "\uD83C\uDF55" = 🍕 = 2 car deux paires UTF-16
Faire une application Unicode Ready
📏 Quelques règles à respecter 📐
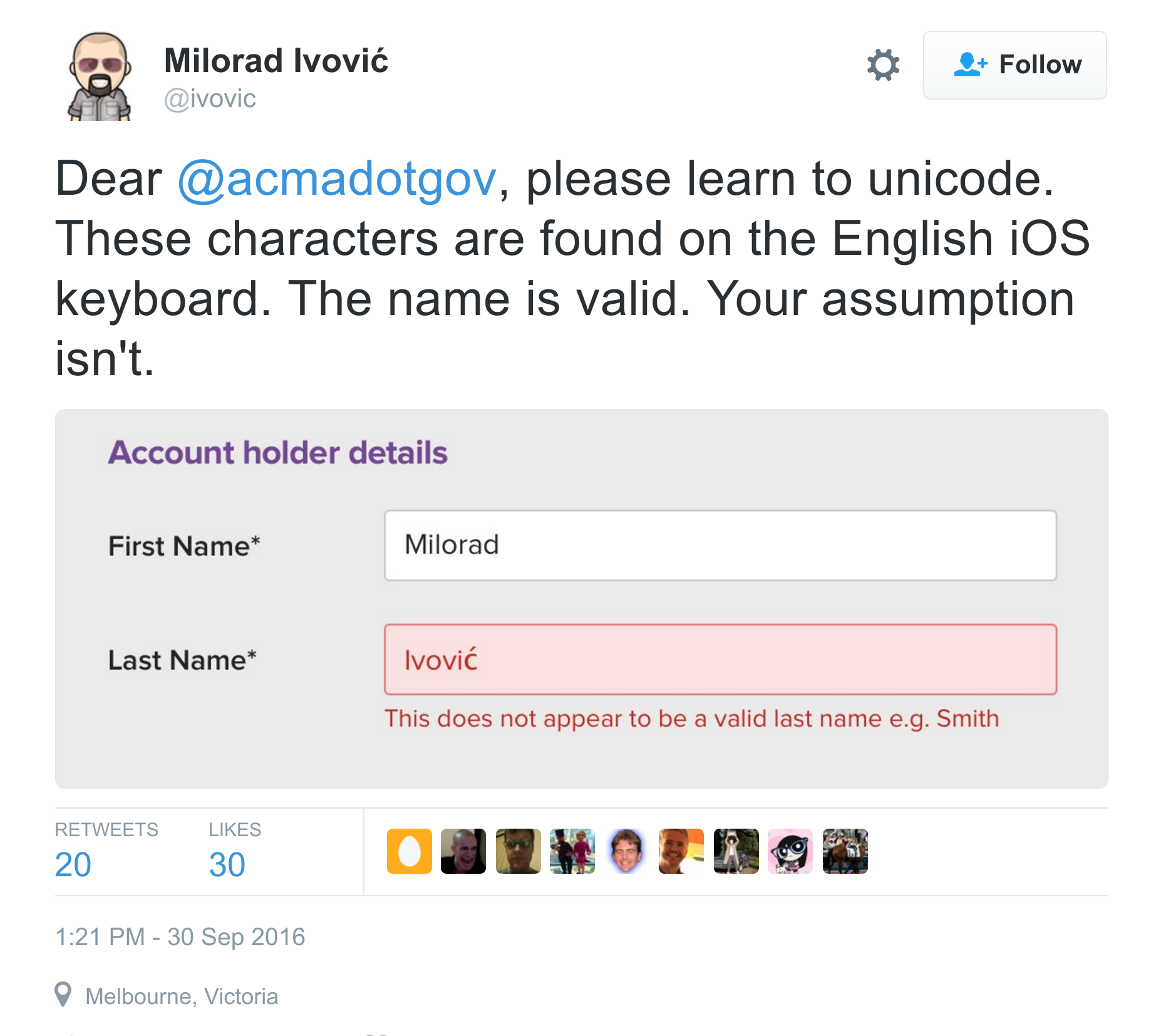
Votre responsabilité d'artisans du Web
Sur les 260 000 possibilités qu'offre Unicode,
pourquoi limiter ?
La normalisation
- Vos utilisateurs saisissent n'importe quoi
- Vous voudriez vous protéger contre certains usages…
- é === é mais é !== e + ◌́
- Caractères invisibles
- Homoglyphes…
La normalisation
-
Trouvez l'intrus :
KevinKevinkevin
- Unicode code point 'KELVIN SIGN' (U+212A) => "K"
- Ceci est un homoglyphe
La normalisation
- KELVIN SIGN, K UPPERCASE, K LOWERCASE :
- Kevin : u"\u212A\u0065\u0076\u0069\u006E"
- Kevin : u"\u004B\u0065\u0076\u0069\u006E"
- kevin : u"\u006B\u0065\u0076\u0069\u006E"
- Doit être idempotent, et à jour !
- Tout est défini dans Unicode
GitHub password reset (2016)
- Demande de mot de passe oublié
- L'email est normalisé au moment du lookup en BDD
- Un token pour l'email A est généré et envoyé à l'email B !
- mike@example.org != miᏦᎬ@example.org
- Attaque par homoglyphe 😈
https://bounty.github.com/researchers/jagracey.html
Charset "utf8" dans MySQL
utf8dans MySQL ne supporte pas tout Unicode- Seulement 3 octets
- Seulement la BMP 😢
- Un caractère inconnu provoque la fin de la chaîne
"utf8mb4" pour tous !
utf8truncate vos contenusstrict modeest désactivé par défaut 😞
Utilisez utf8mb4 !
Quelques Pro-tips ©
- Utilisez http://editorconfig.org/
[*] charset = utf-8 - Toujours forcer le charset de vos connexions MySQL
- Ne plus utiliser
utf8maisutf8mb4 - Normalisez avec les bons outils, et de façon homogène
- Investissez plus de temps sur Unicode
Merci pour votre
😘 attention 👋
@damienalexandre
